Lanczos algorithm
From Wikipedia, the free encyclopedia
The Lanczos algorithm is an iterative algorithm invented by Cornelius Lanczos that is an adaptation of power methods to findeigenvalues and eigenvectors of a square matrix or the singular value decomposition of a rectangular matrix. It is particularly useful for finding decompositions of very large sparse matrices. In Latent Semantic Indexing, for instance, matrices relating millions of documents to hundreds of thousands of terms must be reduced to singular-value form.
Peter Montgomery published in 1995 an algorithm, based on the Lanczos algorithm, for finding elements of the nullspace of a large sparse matrix over GF(2); since the set of people interested in large sparse matrices over finite fields and the set of people interested in large eigenvalue problems scarcely overlap, this is often also called the block Lanczos algorithm without causing unreasonable confusion. See Block Lanczos algorithm for nullspace of a matrix over a finite field.


 0.
0.
 ,
, 
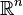 .
.