
Strictly speaking matrix management is the practice of managing individuals with more than one reporting line (in a matrix organization structure), but it is also commonly used to describe managing cross functional, cross business group and other forms of working that cross the traditional vertical business units – often silos – of function and geography.
A lot of the early literature on the matrix comes from the field of cross functional project management where matrices are described as strong, medium or weak depending on the level of power of the project manager.
Some organizations fall somewhere between the fully functional and the pure matrix. These organizations are defined in A Guide to the Project Management Body of Knowledge[1] as ’composite’. For example, even a fundamentally functional organization may create a special project team to handle a critical project.
However, today, matrix management is much more common and exists at some level, in most large complex organizations, particularly those that have multiple business units and international operations.
Key advantages that organizations seek when introducing a matrix include:
- To break business information silos – to increase cooperation and communication across the traditional silos and unlock resources and talent that are currently inaccessible to the rest of the organization.
- To deliver work across the business more effectively – to serve global customers, manage supply chains that extend outside the organization, and run integrated business regions, functions and processes.
- To be able to respond more flexibly – to reflect the importance of both the global and the local, the business and the function in the structure, and to respond quickly to changes in markets and priorities.
- To develop broader people capabilities – a matrix helps develop individuals with broader perspectives and skills who can deliver value across the business and manage in a more complex and interconnected environment.
Key disadvantages of matrix organizations include:
- Mid-level management having multiple supervisors can be confusing, in that competing agendas and emphases can pull employees in different directions, which can lower productivity.
- Mid-level management can become frustrated with what appears to be a lack of clarity with priorities.
- Mid-level management can become over-burdened with the diffusion of priorities.
- Supervisory management can find it more difficult to achieve results within their area of expertise with subordinate staff being pulled in different directions.
The advantages of a matrix for project management can include:
- Individuals can be chosen according to the needs of the project.
- The use of a project team that is dynamic and able to view problems in a different way as specialists have been brought together in a new environment.
- Project managers are directly responsible for completing the project within a specific deadline and budget.
The disadvantages for project management can include:
- A conflict of loyalty between line managers and project managers over the allocation of resources.
- Projects can be difficult to monitor if teams have a lot of independence.
- Costs can be increased if more managers (i.e. project managers) are created through the use of project teams.
Representing matrix organizations visually has challenged managers ever since the matrix management structure was invented. Most organizations use dotted lines to represent secondary relationships between people, and charting software such as Visio and OrgPlus supports this approach. Until recently, Enterprise resource planning (ERP) and Human resource management systems (HRMS) software did not support matrix reporting. Late releases of SAP software support matrix reporting, and Oracle eBusiness Suite can also be customized to store matrix information.
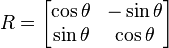
 .
.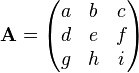

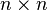

 is the
is the 

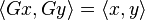

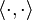 stands now for the standard
stands now for the standard  .
.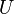 is an n by n matrix then the following are all equivalent conditions:
is an n by n matrix then the following are all equivalent conditions: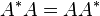

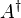 , then the Hermitian property can be written concisely as
, then the Hermitian property can be written concisely as