
Spectral theorem
From Wikipedia, the free encyclopedia
In mathematics, particularly linear algebra and functional analysis, the spectral theorem is any of a number of results about linear operators or about matrices. In broad terms the spectral theorem provides conditions under which an operator or a matrix can bediagonalized (that is, represented as a diagonal matrix in some basis). This concept of diagonalization is relatively straightforward for operators on finite-dimensional spaces, but requires some modification for operators on infinite-dimensional spaces. In general, the spectral theorem identifies a class of linear operators that can be modelled by multiplication operators, which are as simple as one can hope to find. In more abstract language, the spectral theorem is a statement about commutative C*-algebras. See also spectral theory for a historical perspective.
Examples of operators to which the spectral theorem applies are self-adjoint operators or more generally normal operators on Hilbert spaces.
The spectral theorem also provides a canonical decomposition, called the spectral decomposition, eigenvalue decomposition, or eigendecomposition, of the underlying vector space on which the operator acts.
In this article we consider mainly the simplest kind of spectral theorem, that for a self-adjoint operator on a Hilbert space. However, as noted above, the spectral theorem also holds for normal operators on a Hilbert space.
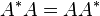

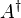 , then the Hermitian property can be written concisely as
, then the Hermitian property can be written concisely as
