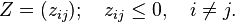The Gram–Schmidt process

where 〈
u,
v〉 denotes the
inner product of the vectors
u and
v. This operator projects the vector
v orthogonally onto the vector
u.
The Gram–Schmidt process then works as follows:


The first two steps of the Gram–Schmidt process
The sequence
u1, …,
uk is the required system of orthogonal vectors, and the normalized vectors
e1, …,
ek form an
orthonormal set. The calculation of the sequence
u1, …,
uk is known as
Gram–Schmidt orthogonalization, while the calculation of the sequence
e1, …,
ek is known as
Gram–Schmidt orthonormalization as the vectors are normalized.
To check that these formulas yield an orthogonal sequence, first compute 〈
u1,
u2〉 by substituting the above formula for
u2: we get zero. Then use this to compute 〈
u1,
u3〉 again by substituting the formula for
u3: we get zero. The general proof proceeds by
mathematical induction.
Geometrically, this method proceeds as follows: to compute ui, it projects vi orthogonally onto the subspace U generated by u1, …,ui−1, which is the same as the subspace generated by v1, …, vi−1. The vector ui is then defined to be the difference between vi and this projection, guaranteed to be orthogonal to all of the vectors in the subspace U.
The Gram–Schmidt process also applies to a linearly independent
infinite sequence {
vi}
i. The result is an orthogonal (or orthonormal) sequence {
ui}
i such that for natural number
n: the algebraic span of
v1, …,
vn is the same as that of
u1, …,
un.
If the Gram–Schmidt process is applied to a linearly dependent sequence, it outputs the 0 vector on the ith step, assuming that vi is a linear combination of v1, …, vi−1. If an orthonormal basis is to be produced, then the algorithm should test for zero vectors in the output and discard them because no multiple of a zero vector can have a length of 1. The number of vectors output by the algorithm will then be the dimension of the space spanned by the original inputs.
Numerical stability
When this process is implemented on a computer, the vectors
uk are often not quite orthogonal, due to
rounding errors. For the Gram–Schmidt process as described above (sometimes referred to as “classical Gram–Schmidt”) this loss of orthogonality is particularly bad; therefore, it is said that the (classical) Gram–Schmidt process is
numerically unstable.
The Gram–Schmidt process can be stabilized by a small modification. Instead of computing the vector uk as

it is computed as

Each step finds a vector

orthogonal to

. Thus
is also orthogonalized against any errors introduced in computation of
. This approach (sometimes referred to as “modified Gram–Schmidt”) gives the same result as the original formula in exact arithmetic and introduces smaller errors in finite-precision arithmetic.
Algorithm
The following algorithm implements the stabilized Gram–Schmidt orthonormalization. The vectors v1, …, vk are replaced by orthonormal vectors which span the same subspace.
-
for j from 1 to k do
-
for i from 1 to j − 1 do
-
 (remove component in direction vi)
(remove component in direction vi)
- next i
-
 (normalize)
(normalize)
- next j
The cost of this algorithm is asymptotically 2
nk2 floating point operations, where
n is the dimensionality of the vectors (
Golub & Van Loan 1996, §5.2.8)