

Best approximation theorem
Best approximation theorem
Theorem
Let X be an inner product space with induced norm, and  a non-empty, complete convex subset. Then, for all
a non-empty, complete convex subset. Then, for all  , there exists a unique best approximation a0 to x in A.
, there exists a unique best approximation a0 to x in A.
a non-empty, complete convex subset. Then, for all , there exists a unique best approximation a0 to x in A.Proof
Suppose x = 0 (if not the case, consider A − {x} instead) and let  . There exists a sequence (an) in Asuch that
. There exists a sequence (an) in Asuch that
. There exists a sequence (an) in Asuch that-
 .
.
-
 .
.
 so
so-
 .
.
Hence
-
 as
as 
 as
as -
 .
.
Since  ,
,  . Furthermore
. Furthermore
, . Furthermore-
 as
as  ,
,
which proves | | a0 | | = d. Existence is thus proved. We now prove uniqueness. Suppose there were two distinct best approximations a0and a0‘ to x (which would imply | | a0 | | = | | a0‘ | | = d). By the parallelogram rule we would have
-
 .
.
Then

 , which means
, which means  , thus completing the proof.
, thus completing the proof.Rotation matrix
Rotation matrix
From Wikipedia, the free encyclopedia
In linear algebra, a rotation matrix is a matrix that is used to perform a rotation in Euclidean space. For example the matrix
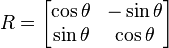
rotates points in the xy–Cartesian plane counterclockwise through an angle θ about the origin of the Cartesian coordinate system. To perform the rotation, the position of each point must be represented by a column vector v, containing the coordinates of the point. A rotated vector is obtained by using the matrix multiplication Rv (see below for details).
In two and three dimensions, rotation matrices are among the simplest algebraic descriptions of rotations, and are used extensively for computations in geometry, physics, and computer graphics. Though most applications involve rotations in two or three dimensions, rotation matrices can be defined for n-dimensional space.
Rotation matrices are always square, with real entries. Algebraically, a rotation matrix in n-dimensions is a n × n special orthogonal matrix, that is an orthogonal matrix whose determinant is 1:
-
 .
.
The set of all rotation matrices forms a group, known as the rotation group or the special orthogonal group. It is a subset of the orthogonal group, which includes reflections and consists of all orthogonal matrices with determinant 1 or -1, and of the special linear group, which includes all volume-preserving transformations and consists of matrices with determinant 1.
http://en.wikipedia.org/wiki/Rotation_matrix
As in two dimensions a matrix can be used to rotate a point (x, y, z) to a point (x′, y′, z′). The matrix used is a 3 × 3 matrix,
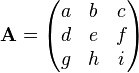
This is multiplied by a vector representing the point to give the result

The matrix A is a member of the three dimensional special orthogonal group, SO(3), that is it is an orthogonal matrix withdeterminant 1. That it is an orthogonal matrix means that its rows are a set of orthogonal unit vectors (so they are an orthonormal basis) as are its columns, making it easy to spot and check if a matrix is a valid rotation matrix. The determinant must be 1 as if it is -1 (the only other possibility for an orthogonal matrix) then the transformation given by it is a reflection, improper rotation or inversion in a point, i.e. not a rotation.
Matrices are often used for doing transformations, especially when a large number of points are being transformed, as they are a direct representation of the linear operator. Rotations represented in other ways are often converted to matrices before being used. They can be extended to represent rotations and transformations at the same time using Homogeneous coordinates. Transformations in this space are represented by 4 × 4 matrices, which are not rotation matrices but which have a 3 × 3 rotation matrix in the upper left corner.
The main disadvantage of matrices is that they are more expensive to calculate and do calculations with. Also in calculations wherenumerical instability is a concern matrices can be more prone to it, so calculations to restore orthonormality, which are expensive to do for matrices, need to be done more often.
Isometry
Isometry
From Wikipedia, the free encyclopedia
- For the mechanical engineering and architecture usage, see isometric projection. For isometry in differential geometry, seeisometry (Riemannian geometry).
In mathematics, an isometry is a distance-preserving map between metric spaces. Geometric figures which can be related by an isometry are called congruent.
Isometries are often used in constructions where one space is embedded in another space. For instance, the completion of a metric space M involves an isometry from M into M’, a quotient set of the space of Cauchy sequences on M. The original space M is thus isometrically isomorphic to a subspace of a complete metric space, and it is usually identified with this subspace. Other embedding constructions show that every metric space is isometrically isomorphic to a closed subset of some normed vector space and that every complete metric space is isometrically isomorphic to a closed subset of some Banach space.
An isometric surjective linear operator on a Hilbert space is called a unitary operator.
Unitary matrix
Unitary matrix
From Wikipedia, the free encyclopedia
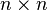

where In is the identity matrix in n dimensions and  is the conjugate transpose (also called the Hermitian adjoint) of U. Note this condition says that a matrix U is unitary if and only if it has an inverse which is equal to its conjugate transpose
is the conjugate transpose (also called the Hermitian adjoint) of U. Note this condition says that a matrix U is unitary if and only if it has an inverse which is equal to its conjugate transpose 
is the conjugate transpose (also called the Hermitian adjoint) of U. Note this condition says that a matrix U is unitary if and only if it has an inverse which is equal to its conjugate transpose

A unitary matrix in which all entries are real is an orthogonal matrix. Just as an orthogonal matrix G preserves the (real) inner productof two real vectors,
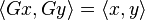
so also a unitary matrix U satisfies

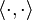 stands now for the standard
stands now for the standard If 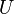 is an n by n matrix then the following are all equivalent conditions:
is an n by n matrix then the following are all equivalent conditions:
is an n by n matrix then the following are all equivalent conditions:-
is unitary
-
is unitary
- the columns of form an orthonormal basis of
 with respect to this inner product
with respect to this inner product - the rows of form an orthonormal basis of with respect to this inner product
-
is an isometry with respect to the norm from this inner product
-
is a normal matrix with eigenvalues lying on the unit circle.
Self-adjoint operator
Self-adjoint operator
From Wikipedia, the free encyclopedia
In mathematics, on a finite-dimensional inner product space, a self-adjoint operator is one that is its own adjoint, or, equivalently, one whose matrix is Hermitian, where a Hermitian matrix is one which is equal to its own conjugate transpose. By the finite-dimensional spectral theorem such operators have an orthonormal basis in which the operator can be represented as a diagonal matrix with entries in the real numbers. In this article, we consider generalizations of this concept to operators on Hilbert spaces of arbitrary dimension.
Self-adjoint operators are used in functional analysis and quantum mechanics. In quantum mechanics their importance lies in the fact that in the Dirac–von Neumann formulation of quantum mechanics, physical observables such as position, momentum, angular momentum and spin are represented by self-adjoint operators on a Hilbert space. Of particular significance is the Hamiltonian

which as an observable corresponds to the total energy of a particle of mass m in a real potential field V. Differential operators are an important class of unbounded operators.
The structure of self-adjoint operators on infinite dimensional Hilbert spaces essentially resembles the finite dimensional case, that is to say, operators are self-adjoint if and only if they are unitarily equivalent to real-valued multiplication operators. With suitable modifications, this result can be extended to possibly unbounded operators on infinite dimensional spaces. Since an everywhere defined self-adjoint operator is necessarily bounded, one needs be more attentive to the domain issue in the unbounded case. This is explained below in more detail.
Spectral theorem
Spectral theorem
From Wikipedia, the free encyclopedia
In mathematics, particularly linear algebra and functional analysis, the spectral theorem is any of a number of results about linear operators or about matrices. In broad terms the spectral theorem provides conditions under which an operator or a matrix can bediagonalized (that is, represented as a diagonal matrix in some basis). This concept of diagonalization is relatively straightforward for operators on finite-dimensional spaces, but requires some modification for operators on infinite-dimensional spaces. In general, the spectral theorem identifies a class of linear operators that can be modelled by multiplication operators, which are as simple as one can hope to find. In more abstract language, the spectral theorem is a statement about commutative C*-algebras. See also spectral theory for a historical perspective.
Examples of operators to which the spectral theorem applies are self-adjoint operators or more generally normal operators on Hilbert spaces.
The spectral theorem also provides a canonical decomposition, called the spectral decomposition, eigenvalue decomposition, or eigendecomposition, of the underlying vector space on which the operator acts.
In this article we consider mainly the simplest kind of spectral theorem, that for a self-adjoint operator on a Hilbert space. However, as noted above, the spectral theorem also holds for normal operators on a Hilbert space.
Normal matrix
Normal matrix
From Wikipedia, the free encyclopedia
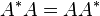
where A* is the conjugate transpose of A. That is, a matrix is normal if it commutes with its conjugate transpose.
If A is a real matrix, then A*=AT; it is normal if ATA = AAT.
Normality is a convenient test for diagonalizability: every normal matrix can be converted to a diagonal matrix by a unitary transform, and every matrix which can be made diagonal by a unitary transform is also normal, but finding the desired transform requires much more work than simply testing to see whether the matrix is normal.
The concept of normal matrices can be extended to normal operators on infinite dimensional Hilbert spaces and to normal elements in C*-algebras. As in the matrix case, normality means commutativity is preserved, to the extent possible, in the noncommutative setting. This makes normal operators, and normal elements of C*-algebras, more amenable to analysis.
Hermitian matrix
Hermitian matrix
From Wikipedia, the free encyclopedia
In mathematics, a Hermitian matrix (or self-adjoint matrix) is a square matrix with complex entries that is equal to its ownconjugate transpose – that is, the element in the i-th row and j-th column is equal to the complex conjugate of the element in the j-th row and i-th column, for all indices i and j:

If the conjugate transpose of a matrix A is denoted by 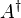 , then the Hermitian property can be written concisely as
, then the Hermitian property can be written concisely as
, then the Hermitian property can be written concisely as
{kind=link}
Hermitian matrices can be understood as the complex extension of real symmetric matrices.
Hermitian matrices are named after Charles Hermite, who demonstrated in 1855 that matrices of this form share a property with real symmetric matrices of having eigenvalues always real.
Spectral radius
Spectral radius
From Wikipedia, the free encyclopedia
In mathematics, the spectral radius of a matrix or a bounded linear operator is the supremum among the absolute values of the elements in its spectrum, which is sometimes denoted by ρ(·).